



Un confronto tra i vari tipo di visione artificiale, in particolare tra i sistemi embedded che raccolgono, elaborano e agiscono sui dati localmente anziché fare affidamento su risorse basate sul cloud.
La visione artificiale si riferisce all’obiettivo tecnologico di portare la visione umana sui computer, consentendo applicazioni dall’ispezione delle catene di montaggio all’assistenza alla guida e alla robotica. I computer non hanno la capacità di intuire la visione e le immagini come gli esseri umani. Dobbiamo invece fornire ai computer algoritmi per risolvere compiti specifici del dominio.
Questo articolo esplora l’intelligenza artificiale (AI) in relazione a come far percepire ai computer il mondo nel modo più simile agli esseri umani tramite gli “occhi” artificiali. Confronterò brevemente ogni tipo di visione artificiale, in particolare nei sistemi embedded che raccolgono, elaborano e agiscono sui dati localmente anziché fare affidamento su risorse basate sul cloud.
Cos’è la visione artificiale?
Negli anni ’60, la visione artificiale svolgeva compiti come leggere il testo da una pagina (riconoscimento ottico dei caratteri) e riconoscere forme come cerchi o rettangoli. Da allora la visione artificiale è diventata uno dei domini principali dell’intelligenza artificiale, che comprende qualsiasi sistema informatico che percepisce, sintetizza o deduce significato dai dati.
Esistono tre approcci alla visione artificiale:
- La visione artificiale convenzionale.
Si riferisce ad algoritmi programmati che risolvono compiti come la stima del movimento, l’unione di immagini panoramiche o il rilevamento di linee. La visione artificiale convenzionale utilizza l’elaborazione e la logica del segnale standard per risolvere i compiti. L’ingegnere seleziona manualmente le funzioni che estraggono significato dalle immagini e utilizza le caratteristiche risultanti all’interno di un algoritmo che risolve il compito. Algoritmi come Canny edge detection o il flusso ottico possono trovare rispettivamente contorni o vettori di movimento, il che è utile per isolare oggetti in un’immagine o tracciare il movimento delle immagini successive. I parametri che necessitano di calibrazione per questa attività o ambiente vengono ottimizzati manualmente o tramite un algoritmo di supporto. - La visione artificiale con machine learning classico.
Richiede un esperto per “creare” il set di funzionalità su cui viene addestrato il modello di machine learning. Molte di queste funzionalità sono comuni alle applicazioni di visione artificiale convenzionali. Non tutte le funzionalità sono utili, quindi è necessaria un’analisi per eliminare quelle non significative; l’algoritmo di apprendimento automatico è addestrato su queste funzionalità per trovare modelli, che potrebbero non essere banali da isolare manualmente. L’implementazione efficace di questi algoritmi richiede esperienza nell’elaborazione delle immagini e nell’apprendimento automatico. -
La visione artificiale con deep learning.
È l’apprendimento automatico, ma su modelli di rete neurale molto grandi che operano su dati “grezzi” in gran parte non elaborati. Il deep learning ha avuto un impatto significativo sulla visione artificiale inserendo operazioni di estrazione delle funzionalità nel modello, in modo tale che l’algoritmo apprende le funzionalità più significative senza richiedere competenze per creare manualmente il set di funzionalità. Il deep learning è in grado di isolare meglio modelli poco percettibili, ma richiede maggiori capacità di calcolo e di memoria.
Quale tipo di visione artificiale è la migliore?
Ciò dipende, in definitiva, da alcuni fattori, rappresentati nella seguente tabella in cui parametri come l’accuratezza e la complessità dell’attività dipendono dal caso d’uso:
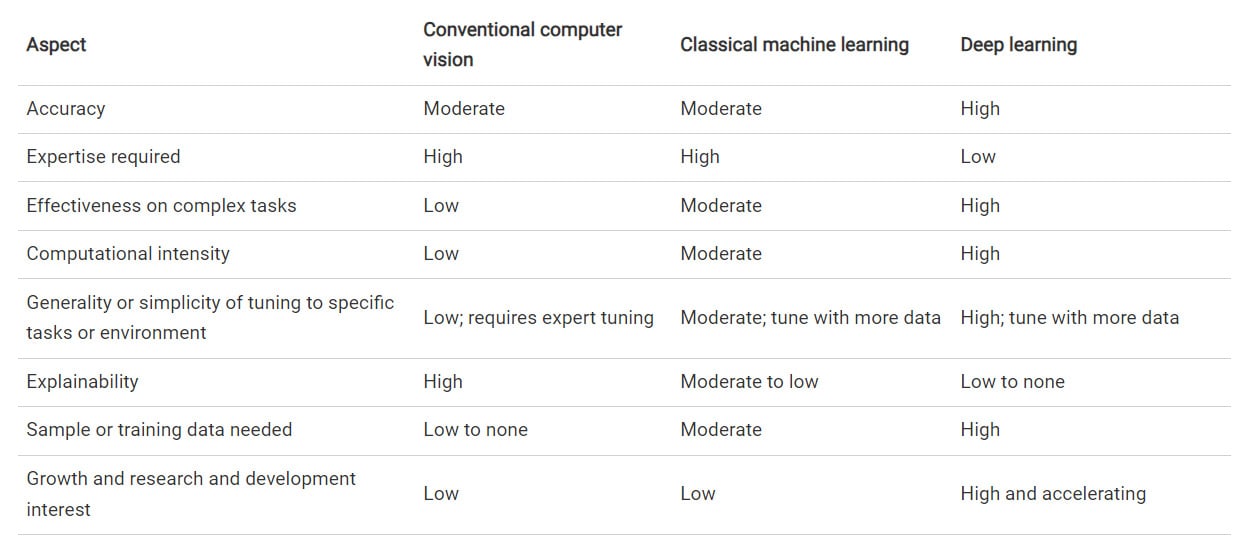
Tabella 1: Confronto tra le tecnologie di visione artificiale
La visione artificiale con l’apprendimento automatico classico si colloca tra i metodi convenzionali e quelli di deep learning; l’insieme delle applicazioni che traggono vantaggio rispetto agli altri due approcci è ridotto. La visione artificiale convenzionale può essere accurata ed estremamente efficiente in applicazioni semplici, ad alto rendimento o critiche per la sicurezza. Il deep learning è il più generale, il più semplice da sviluppare e offre la massima precisione in applicazioni complesse, come l’identificazione di un minuscolo componente mancante durante la verifica dell’assemblaggio di circuiti stampati (PCB) in circuiti ad alta densità.
Alcune applicazioni beneficiano di più tipi di algoritmi di visione artificiale che operano in tandem, per coprire i reciproci punti deboli. Questo approccio è comune nelle applicazioni critiche per la sicurezza con ambienti altamente variabili, come i sistemi di assistenza alla guida. Ad esempio, è possibile utilizzare il flusso ottico impiegando metodi convenzionali di visione artificiale insieme a un modello di deep learning per tracciare i veicoli vicini e utilizzare un algoritmo per fondere i risultati per accertare se i due approcci concordano. In caso contrario, il sistema potrebbe avvisare il conducente o avviare una manovra di sicurezza.
Un’alternativa è utilizzare più tipi di visione artificiale in sequenza. Un lettore di codici a barre può utilizzare il deep learning per individuare le regioni di interesse, ritagliarle e quindi utilizzare un algoritmo di visione artificiale convenzionale per decodificarle.
Vantaggi del deep learning nelle applicazioni di visione artificiale
Rispetto alla visione artificiale convenzionale e al machine learning classico, il deep learning ha una precisione costantemente maggiore e sta rapidamente migliorando, poiché è immensamente popolare nelle comunità di ricerca, open source e commerciali. La Figura 1 riassume la differenza nel flusso di dati dal punto di vista dello sviluppatore per le tre tecnologie.
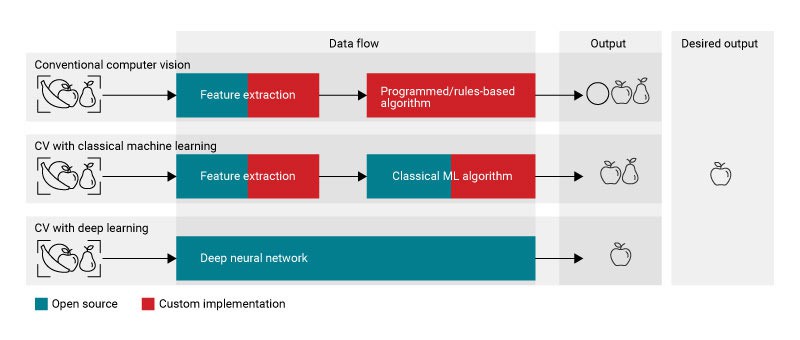
Figura 1: flusso di dati per ciascun approccio alla visione artificiale.
Il deep learning richiede un’intensa attività computazionale. Tuttavia, miglioramenti nella potenza di elaborazione, velocità, acceleratori (come unità di elaborazione neurale e unità di elaborazione grafica) e un migliore supporto software per operazioni su matrici e vettori hanno mitigato i maggiori requisiti computazionali, anche sui sistemi embedded. Microprocessori come AM62A7 sfruttano gli acceleratori hardware per eseguire algoritmi di deep learning a frame rate elevati.
Visione artificiale in pratica
I processori del portafoglio Texas Instruments AM6xA come AM62A7 contengono hardware di accelerazione del deep learning e software di supporto per attività di visione artificiale convenzionali e di deep learning. I core del processore di segnale digitale come il C66x e gli acceleratori hardware per il flusso ottico e la stima della profondità stereo consentono inoltre attività di visione artificiale convenzionali ad alte prestazioni su processori come TDA4VM e AM68PA.
Con processori capaci sia di visione artificiale convenzionale che di deep learning, è possibile creare strumenti che rivaleggiano con i sogni fantascientifici. I carrelli della spesa automatizzati semplificheranno gli acquisti; i robot chirurgici e medici guideranno i medici verso i primi segni di malattia; i robot mobili taglieranno i prati e consegneranno i pacchi.
Alla pagina edge AI Vision di Texas Instruments è possibile scoprire come la visione artificiale embedded sta cambiando il mondo.
Reese Grimsley è Systems Applications presso Texas Instruments.

{kind=link}